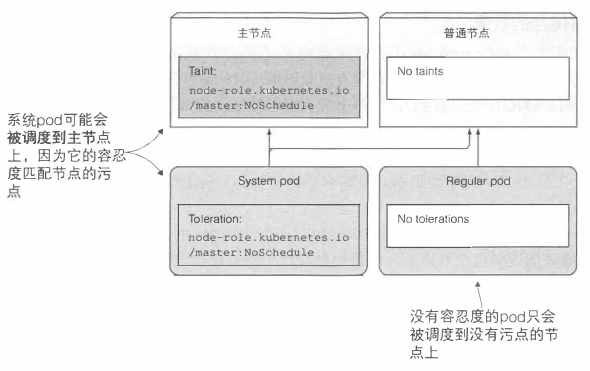
- 节点选择器和节点亲缘性规则,是通过明确的在 Pod 中添加信息,来决定一个 Pod 可以或者不可以被调度到哪些节点上。而污点则是在不修改巳有 Pod 信息的前提下,通过在节点上添加污点信息,来拒绝 Pod 在某些节点上的部署
一、污点和容忍度
1. 介绍污点和容忍度
- 污点包含了一个 key、value,以及一个 effect,表现为
<key>=<value>:<effect> - 显示节点的污点信息:
1 | $ kubectl describe node debian201 | grep -i taint |
- 污点将阻止 Pod 调度到这个节点上面,除非 Pod 能容忍这个污点
- 显示 Pod 的污点容忍度:
1 | $ kubectl describe pod -n kube-system kube-proxy-rgpn2 | grep -i toleration -A 7 |
- 节点可以有多个污点,Pod 可以有多个污点容忍度。污点可以只有一个 key 和一个效果,而不必设置 value。污点容忍度可以通过设置 Equal 操作符匹配指定的 value,也可以设置 Exists 操作符匹配污点的 key
- 污点的效果:
NoSchedule:如果 Pod 没有容忍这些污点,Pod 就不能调度到该节点PreferNoSchedule:是 NoSchedule 的宽松版本,尽量阻止 Pod 调度到该节点,特殊情况可以调度NoExecute:前两者只在调度期间起作用,NoExecute 会影响正在节点上运行的 Pod。如果添加了该效果的污点,在节点上运行的 Pod 如果没有容忍污点,将会被驱逐
2. 添加自定义污点
- 案例:隔离生产环境
1 | $ kubectl taint node debian202 type=prod:NoSchedule |
3. 在 Pod 上添加污点容忍度
1 | $ vim deploy.yaml |
4. 节点失效后的 Pod 重新调度等待时间
- NoExecute 污点同时还可以设置,当 Pod 运行的节点变成 unreachable 或者 unready 状态,Pod 需要重新调度时,控制面板的最长等待时间
- 这两个容忍度会自动添加到 Pod 上
1 | $ kubectl get pod backend -o yaml |
二、Pod 的节点亲缘性
- 污点可以让 Pod 远离特定的节点,亲缘性可以让 Pod 只调度在某些节点
1. 强制性节点亲缘性
- 使用节点选择器将 Pod 调度到指定节点:
1 | apiVersion: v1 |
- 使用节点亲缘性将 Pod 调度到指定节点:
1 | apiVersion: v1 |
requiredDuringScheduling...表明该 Pod 能够调度的节点必须包含指定的标签...IgnoredDuringExecution表明如果去除节点上的标签,不会影响已经在节点上运行的 Pod
2. 优先级节点亲缘性
- 场景:Pod 调度时优先考虑某些节点
1 | apiVersion: v1 |
preferredDuringScheduling...表明调度 Pod 时优先考虑带指定标签的节点- 除了节点亲缘性的优先级函数,调度器还会考虑其他的优先级函数来决定 Pod 被调度到哪。比如 TopologySpread 确保属于同一个 ReplicaSet 或者 Service 的 Pod 尽可能分散部署在不同节点上,以避免单个节点宕机导致服务不可用
三、Pod 间亲缘性
- 上述亲缘性规则只影响了 Pod 和节点之间的亲缘性,Pod 自身之间也可以指定亲缘性。比如保证前后端 Pod 尽量部署在同一个节点
1. 多个 Pod 部署在同一节点上
- 部署后端 Pod:
1 | $ kubectl run backend -l app=backend --image busybox -- sleep 999999 |
- 使用 Pod 亲缘性部署前端 Pod:必须(
requiredDuringScheduling)部署到匹配 Pod 选择器(app: backend)的节点(topologyKey: kubernetes.io/hostname)上 - 标签选择器默认匹配同一命名空间中的 Pod。可以在 labelSelector 同一级添加 namespaces 字段,实现从其他的命名空间选择 Pod
1 | apiVersion: apps/v1 |
- 检查:
1 | $ kubectl get pod -o wide |
- 如果此时删除后端 Pod,并重新创建,则后端 Pod 仍会被调度到 debian202(调度器会考虑目前运行中的 Pod 的亲缘性规则)
2. 多个 Pod 部署在同一机柜、区域或地域
- 场景:不希望前端 Pod 部署在同一节点上,但仍希望和后端 Pod 保持足够近,比如在同一个区域中
- 如果节点运行在不同的区域中,需要将
topologyKey属性设置为topology.kubernetes.io/zone,以确保前后端 Pod 运行在同一个区域中。如果运行在不同的地域,需要将topologyKey属性设置为topology.kubernetes.io/region topologyKey表示被调度的 Pod 和另一个 Pod 的距离,值可以自定义。比如为了让 Pod 部署在同一个机柜,可以给每个节点打上rack=<机柜号>的标签,定义 Pod 时将topologyKey的值设置为rack。标签选择器匹配了运行在 Node 12 的后端 Pod,该节点 rack 标签的值等于 rack2。所以调度该 Pod 时,调度器只会在包含标签 rack=rack2 的节点中进行选择- 当调度器决定调度 Pod 时,它首先检查 Pod 的
podAffinity配置,找出那些符合标签选择器的 Pod。接着查询这些 Pod 运行在哪些节点上,特别的是,它会寻找标签能匹配topologyKey的节点,并优先选择标签匹配的节点进行调度

3. 优先级 Pod 间亲缘性
- 场景:优先将前后端 Pod 部署在同一个节点上,如果不满足需求,可以调度到其他节点上
1 | apiVersion: apps/v1 |
- 检查:
1 | $ kubectl get pod -o wide |
4. Pod 间非亲缘性
- 场景:不让两个 Pod 部署在同一个节点上。比如两个 Pod 如果运行在同一个节点上会影响彼此的性能,或者让一组 Pod 分散到不同的区域,保证服务的高可用
- 仅仅将
podAffinity换成podAntiAffinity,其他使用方法和之前类似
1 | apiVersion: apps/v1 |
- 检查:
1 | $ kubectl get pod -o wide |