一、生产者发送原理
1. 发送流程

- Interceptors:拦截器,对数据进行处理(可选,一般不用)
- Serializer:序列化器,对数据序列化(Java 序列化器比较重,有效数据占比低)
- Partitioner:分区器,对数据进行分区处理,在内存中完成
- RecordAccumulator:一个队列容器类,默认 32M,每个分区对应一个队列
- 双端队列,一边从内存池申请内存(创建批次数据),一边释放内存(应答后删除数据)
- Sender:将缓冲队列中的数据发送到 Kafka 集群
- Sender 发送数据的条件:
batch.size:批次数据量达到后发送,默认 16Klinger.ms:批次数据量未达到 batch.size,经过 linger.ms 时间后发送,默认 0ms,表示直接发送
- Sender 发送流程:
- 分区数据要发往不同的 Broker 节点,以节点 broker id 为 key,需要发送的数据为 value,形成一个 request 请求,放在 InFlightRequests 队列中
- 若请求没有及时应答,仍可以继续发送请求,但每个 Broker 节点最多缓存 5 个请求
- 发送到 Broker 后,集群通过副本同步机制创建副本
- 若应答成功,生产者清理请求,并且清理缓冲队列中的数据
- 若应答失败,则请求重试,次数为
retries,默认为 int 的最大值,直到重试成功
- Sender 发送数据的条件:
- Selector:打通发送数据到 Broker 的链路
2. 应答机制
acks:- 0:生产者发送的数据无需 Leader 应答。若 Leader 宕机且未落盘,则数据丢失。生产环境一般不用
- 1:生产者发送的数据 Leader 落盘后应答。若 Leader 落盘应答后宕机,但尚未同步副本,则数据丢失(新的 Leader 没有该数据)。一般用于日志传输
- -1/all:生产者发送的数据 Leader 和 ISR 队列的节点落盘后应答。一般用于可靠性要求高的场景,如金钱交易
- 如果分区副本设为 1 个,或者 ISR 里应答的最小副本数量(
min.insync.replicas,默认 1)设为 1 个,此时相当于 ack 为 1
- 如果分区副本设为 1 个,或者 ISR 里应答的最小副本数量(
- ISR 队列:
- Leader 维护了一个动态的 in-sync replica set(ISR)队列,表示和 Leader 保持同步的 Follower + Leader 集合(如 Leader: 0,ISR: 0,1,2)
- 如果 Follower 一段时间(
replica.lag.time.max.ms,默认 30s)未向 Leader 发送通信请求或同步数据,则该 Follower 会从 ISR 队列中移除
2. 生产者重要参数
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | Broker 地址,用逗号分隔 |
| key.serializer / value.serializer | 序列化类型的全类名 |
| buffer.memory | RecordAccumulator 缓冲区总大小,默认 32M |
| batch.size | 缓冲区一批数据的最大值,默认 16K |
| linger.ms | 如果数据未达到 batch.size,sender 等待 linger.time 后发送数据。默认 0ms,建议 5~100ms |
| acks | 见上文,默认 -1 |
| max.in.flight.requests.per.connection | 允许最多没有返回 ack 的次数,默认 5,开启幂等性要保证该值是 1~5 |
| retries | 消息发送失败时,系统重发消息的重试次数,默认 int 最大值。如果开启重试且要保证有序性,需设 max.in.flight.requests.per.connection 为 1,否则重试时其他消息可能发送成功了 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认 100ms |
| enable.idempotence | 是否开启幂等性,默认 true |
| compression.type | 生产者发送数据的压缩方式,默认 none,可设置为 gzip、snappy、lz4、zstd |
二、生产者 API
1. 环境准备
- 引入 Maven 依赖
1 | <dependency> |
2. 异步发送
- 数据发送到缓冲队列就返回,由 Sender 线程处理发送
- 普通异步发送:
1 | public class MyProducer { |
- 回调异步发送:
1 | for (int i = 0; i < 5; i++) { |
3. 同步发送
- 等待 Broker 应答后才把下一条数据放到缓冲队列
1 | for (int i = 0; i < 5; i++) { |
三、生产者分区
1. 分区作用
- 便于合理使用存储资源:可以把海量的数据按照分区切割成多块数据存储在多台 Broker 上,分区也可以实现负载均衡的效果(如根据服务器的存储能力控制分区)
- 提高并行度:生产者可以以分区为单位发送数据,消费者可以以分区为单位消费数据(多线程处理)
2. 分区策略
- 默认分区器:
DefaultPartitioner- If a partition is specified in the record, use it
- If no partition is specified but a key is present, choose a partition based on a hash of the key(如以表名为 key)
- If no partition or key is present, choose the sticky partition that changes when the batch is full(黏性分区:随机选一个分区,待达到 batch.size 或超过 linger.ms,再随机选另一个分区)
1 | public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {..} |
3. 自定义分区器
- 实现
Partitioner接口
1 | public class MyPartitioner implements Partitioner { |
- 使用自定义分区器:
1 | // 此时若指定partition,还按指定的,否则按该分区器 |
四、生产经验
1. 提高吞吐量
1 | // batch.size:批次大小,默认16K |
2. 数据可靠性
- 至少一次:ack 级别为 -1,分区副本数大于 1,ISR 里应答的最小副本数(
min.insync.replicas,默认 1)大于 1 - ack 为 -1 时,若 Leader 和 ISR 队列的节点落盘后,Leader 未应答宕机,此时新的 Leader 仍会接收到数据,会导致重复数据
- 精确一次:开启幂等性 + 开启事务 + 至少一次
1 | // acks:应答策略,默认-1 |
3. 幂等性和事务
- Kafka 0.11 版本后,引入新特性:幂等性和事务
(1) 幂等性
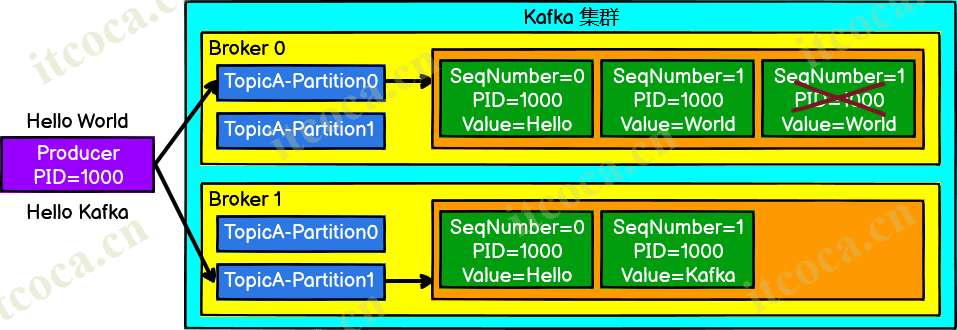
- Producer 不论向 Broker 发送多少次重复数据,Broker 端都只会持久化一条,保证了不重复
- 重复数据的判断标准:具有
<PID, Partition, SeqNumber>相同键的消息提交时,Broker 只会持久化一条- PID:Kafka 每次重启都会分配一个新的
- Partition:分区号
- SeqNumber:单调递增,表示每一个请求
- 幂等性只能保证的是在单分区单会话内不重复,若 Kafka 重启,仍可能产生重复数据(新的 PID)
- 开启幂等性:
enable.idempotence,默认 true
(2) 事务
- 幂等性只能保证单分区单会话,因此需要事务的支持。事务底层依赖幂等性,开启事务必须开启幂等性

- Producer 在使用事务功能前,必须先自定义一个唯一的
transactional.id,这样即使 Kafka 重启也能继续处理未完成的事务 - 事务协调器用于处理事务。事务在提交过程中需要将一些信息持久化到磁盘,该信息就存储在特定的主题中
- 事务协调器的选择:每个 Broker 节点都有事务协调器。存储事务信息的主题默认有 50 个分区,每个分区处理一部分事务。事务会选择分区
hash(transactional.id) % 50对应的 Leader 副本所在的 Broker 节点中的事务协调器去处理
1 | // 指定事务ID |
4. 数据有序
- 生产者发送的数据会进行分区处理,因此消费者消费到的数据不一定是有序的

- 单分区内有序:
- 每个 Broker 节点默认最多缓存 5 个请求(
max.in.flight.requests.per.connection)。开启幂等性后,Kafka 服务端会根据请求序列号按序落盘(序号有误时先放内存不落盘) - Kafka 1.x 版本前,可设置 max.in.flight.requests.per.connection = 1
- Kafka 1.x 版本后,若未开启幂等性,则需设置 max.in.flight.requests.per.connection = 1;若开启幂等性,其值可设置为 1~5
- 每个 Broker 节点默认最多缓存 5 个请求(
- 多分区内有序:消费者拉取每一个分区的数据,统一排序后消费